
Why You (usually) Want a Clustered Index
Note: I originally wrote this a few years ago but never posted it. It resurfaced when I migrated the blog so it’s being posted now.
After watching Kevin Kline’s (blog | twitter) webinar Essential Tasks to a Successful Cloud Migration, I downloaded the T-SQL scripts to run them against some of my databases. One of the included queries identifies tables with forwarded fetches and right on top of the list was a table with over 1.6 billion forwarded fetches in the roughly 3 weeks since the instance was last restarted.
Forwarded Fetches?
1.6 billion of anything collected over three weeks is probably not a good thing, unless it’s pennies into my bank account. What are these forwarded fetches?
In SQL Server, a forwarded record may be created when a row in a heap table is updated. Rather than being updated in-place, a copy of the record is made and if that copy can’t be kept on the same data page, it’ll be put on another page. The original record is updated with a pointer saying “no, the data you want is over on this other page, you should look over there.” When the record is read, you get a forwarded fetch.
Now imagine updating the same record multiple times, and a forwarded record being created each time. Reading a single record might involve a half-dozen or more forwarded fetches. You’re jumping from Greenland to Iceland to Scotland and hoping you don’t get your feet wet. This can really hurt performance.
About That Table
The table in question is one of the drivers for a daily job that sends emails out. Records are collected on it through the day, then this job kicks off and processes the records. It usually takes about six minutes to run each day.
The table is a heap and each record will be updated at least twice. It also has an IDENTITY column which is both unique and ever-increasing. A good candidate for a clustered primary key (one could probably make an argument for a different field being the clustering key, but this field works well enough).
Impact
Before creating the clustered index, I need to know what I’m starting with. Let’s take a look at how things run in the current state.
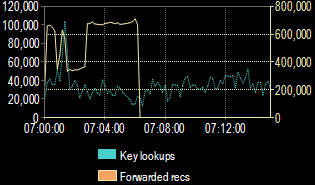
During the six-minute runtime of the job, SentryOne Monitor was reporting that I was dealing with over 400K forwarded records per second. For several minutes. Yikes!
Here’s what I saw the following day, after creating the clustered index.
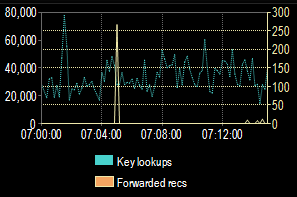
Barely a blip! What you can’t see from this, aside from the amount of time we were churning through forwarded records, is that the job ran in only thirteen seconds and sent 25% more notifications than the previous day. That’s an outstanding improvement!
I Broke Some Rules
I have to confess that I broke the rules of troubleshooting and performance testing because I changed multiple things at once. Not only did I create the clustered index on the table, I also created a nonclustered index to support the most common query used by the daily job.
What I should have done is each of the following steps, in order, with enough time between them to properly evaluate the impact of each.
ALTER TABLE REBUILDon the heap. This may have alleviated the most pressing concern temporarily by eliminating the forwarded records, but we can safely assume they would start to pile up over time.- Add the clustered index. This will permanently fix the forwarded records but may or may not improve job performance. Creating a clustered index also has a side effect of rebuilding the table. So the above step has to happen first.
- Add the nonclustered index to the table if job performance is still not where we’d like it to be.
But it all worked out fine and I was happy with the results. If the nonclustered index wasn’t really needed, maybe we’d eke out a tiny bit of extra performance when working with the table. It’s probably not worth worry about anymore anyway.