
T-SQL Tuesday #124 - I'm a Query Store Newbie
T-SQL Tuesday is a monthly blog party hosted by a different community blogger each month, and this month Tracy Boggiano (blog | twitter) asks us to talk about Query Store, whether we’re using it or not.

For this T-SQL Tuesday, write about your experience adopting Query Store, maybe something unique you have seen, or a how your configure you databases, or any customization you done around it, or a story about how it saved the day. Alternately, if you have not implemented yet blog about why if you are using 2016 and above, we know why if aren’t on 2016. If you are unfortunate to be on below 2016 write about what in Query Store you are looking forward to the most once you are able to implement it. Basically, anything related to Query Store is in for T-SQL Tuesday, hopefully everyone has read up on it and knows what it can do.
I’ll be completely honest here - I expected to sit this one out. I was so certain that I even scheduled another post to be published today, and I don’t think I’ve ever published two posts in the same day before. I’ve had Query Store enabled for a while, but haven’t really done anything with it. Just had it sitting there for the “when I might need it/be ready for it” eventuality.
But then this happened.
Dear diary: today I forced my first query plan via Query Store
At least until we can re-evaluate the query and eliminate or rewrite it.
- Tweet by me on Tue Mar 10 16:27:02 +0000 2020
@erinstellato I was going to sit this #tsqltuesday out but maybe now I need to blog about what I did, how I found it, and why
- Tweet by me on Tue Mar 10 17:57:08 +0000 2020
The Setup
The developers I work with recently completed the development and testing efforts needed to flip a production database over to a current compatibility level (from 100 previously). With that came the move to the “new"It’s six years old, but we’re still calling it “new” Cardinality Estimator. While things generally went well, there were a few queries that didn’t play as nicely with the new CE.
While I have an industry-leading SQL Server monitoring suite watching my servers 24/7, it doesn’t capture full details for everything - by design. But something nudged me today to look in Query Store just to check up on things. I’ve had Query Store enabled for a few months, but haven’t really looked at it on a regular basis. Like Extended Events, it’s a constant entry on my “gotta read up on this stuff” list.
I apologize for the low number and quality of screenshots in this post. As noted above, I didn’t plan to write this at all. I didn’t do a good job of capturing things as they were discovered. But I think you’ll get the gist.
What I Found
My first (and last) stop was the Regressed Queries report, where I found a few stored procedures which had increased significantly in CPU consumption over the past couple days. What you’re seeing here isn’t what I saw at the beginning of the day. The selected procedure (in green) was one notch over to the left, and stood well above all other regressed queries.
Aside: Can we talk for a moment about how easy Microsoft makes it to share screenshots like this, because there’s no sensitive information, no object names, nothing at all to worry about? I keep looking for something that I need to redact but it’s clean!
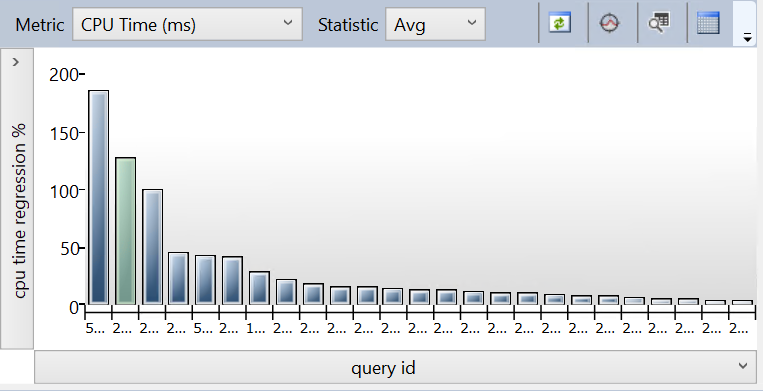
Looking closer, this procedure had definitely increased in runtime - from sub-10ms to over 100ms! Definitely not enough for my monitoring tools to capture as a “long-running query”, but Query Store sure noticed. In terms of raw clock time, it’s still a pretty quick query. But what my monitoring suite did pick up is that this procedure runs over 100 times every minute. That means that the extra 90ms or so is going to add up in a big hurry.
When did this regression start? Let’s look at the daily runtime averages & plans for this procedure.
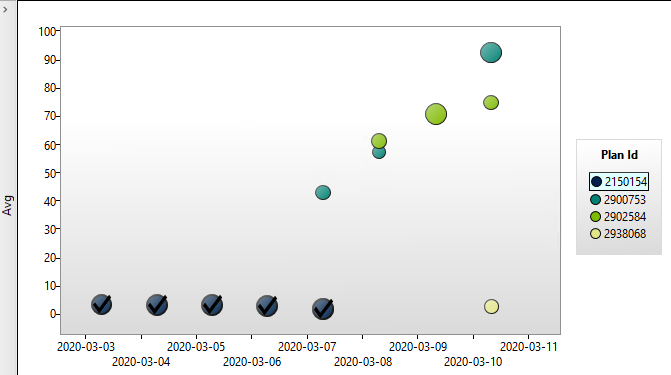
Can you guess when we made the compatibility level change in the database?
Looking closer at the two types of query plans, I saw that the “good” one was using an index seek, while the “bad” performed a full scan of that same table. I told Query Store to force that plan from last week, and things seem to be settling down a bit.
We’ve Come a Long Way
In a previous job, we had to use plan guides to nudge SQL Server in the right direction for executing some queries in a particular way. Query Store is less invasive, easier to implement, and much easier to visualize and explain what you’re seeing and how to get back to a good query plan.
This was a pretty basic and probably naive usage of Query Store. And I do need to check back in on things and make sure that there is a measurable improvement coming from forcing this plan. It’s quite possible that I did something completely wrong! I’ll have to settle in with Erin’s many blog posts on Query Store, and probably pick up Tracy’s book as well.
Next Steps
As was mentioned in the tweets above, this is only a temporary solution! I’m just buying some time while we investigate the stored procedure and its usage.
I spent a few additional minutes with a member of the development team to investigate where and how this procedure is used. We found that it runs on quite a few page loads. Do we need to be doing it so frequently? Can we cache the results at the application layer? Do we even understand the logic buried in the view that’s at the core of the index seek/table scan “toggle”? Is that needed? Can it be done better? Do we need to adjust indexes? Questions to answer another day. When we get those addressed, we’ll remove the forced plan.
But for now, let’s talk about that chocolate…