
Modernizing Your T-SQL: String Aggregation
This is another in a group of several posts on modernizing T-SQL code with new features and functionality available in SQL Server.
SQL Server 2016 gave us the STRING_SPLIT() function, but what about the reverse - compiling a set of values into one delimited string? We only had to wait 15 months for the release of SQL Server 2017, and the STRING_AGG() function.
Setup
For this post, I’m using the set of North American telephone area codes sourced from the North American Numbering Plan Administrator. It’s a really simple table, but that makes it perfect for this example. The whole table is 389 records and two columns each.
The desired result of each query: one record per location, with every area code corresponding to that location grouped into a single comma-separated string.
The Old-Fashioned Way
If we wanted to compile a set of values into a single comma-separated string prior to SQL Server 2017, we had to use what I call “the STUFF()/FOR XML trick”.
This works, but the syntax is a little clunky. If you have multiple instances of it in a single query, it really clutters things up (even with a good auto-formatter). Rarely does anyone write one of these from scratch - we usually copy from a previous query (just like dynamic PIVOTs, right?). Plus, it uses DISTINCT which can be a code smell. It’s not wrong to use it in this situation, but if I’m doing a code review this will be a trigger for me to take a closer look.
The New Kid in Town
With SQL Server 2017, we can use the new STRING_AGG() function to simplify and clean up our syntax. Other RDBMSs have had this function (or a similar one) for a while, so SQL Server is kind of catching up here. But that’s good news!
That almost seems too easy, doesn’t it? No DISTINCT, no subqueries, no additional table references, nothing. Jut give STRING_AGG() the field to roll up, and the delimiter to use between values. SQL Server’s doing a lot of work to help us here!
Is it Worth It?
Short answer: Microsoft probably wouldn’t have done this work if they didn’t see value in it.
Long answer: Let’s test.
I ran both queries through SentryOne Plan Explorer to capture both reads and CPU costs in one go. First is the original method, then the STRING_AGG() method.

This is a huge difference! We’re doing a lot more I/O with the old method, and a much higher estimated cost. To be fair, both costs are well under one Query Buck because this query is so trivial; the real story here is all that I/O. This is a tiny table, and this query performed nearly 6300 reads. What if the table were 100 times larger?
Let’s check out the execution plans.
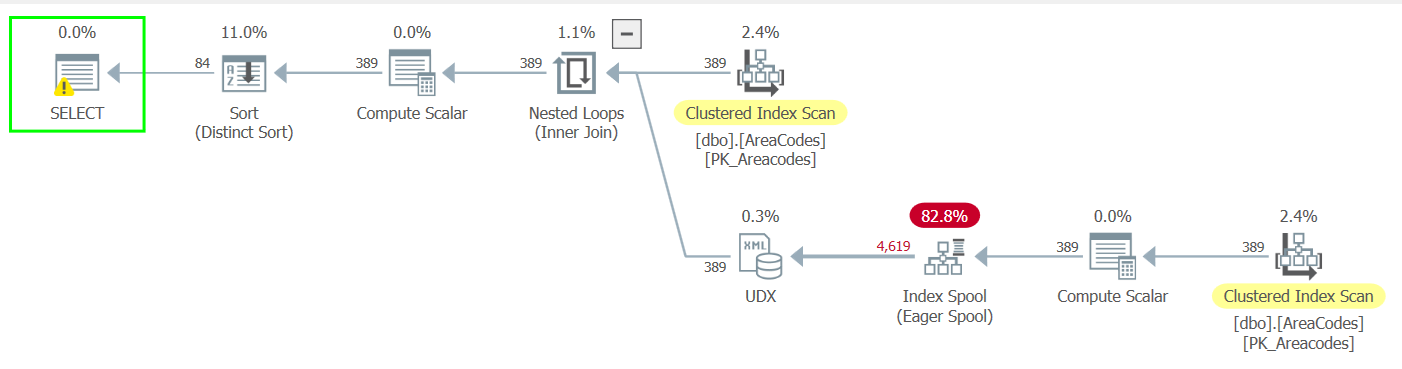
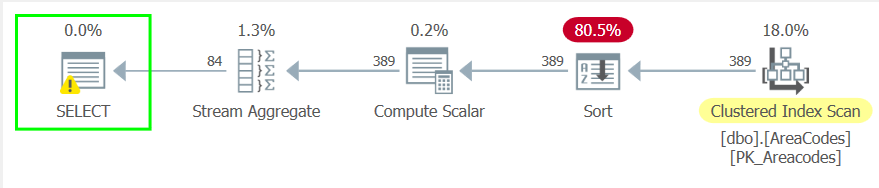
In the pre-2017 version, we’re scanning the clustered index twice and there’s an index spool involved. A lot of data is getting moved around, and this jives with what we saw for the read counts above. On the other hand, the STRING_AGG() version is much more I/O-efficient.
But Wait, There’s More!
What if I need these area codes to display in ascending order? I haven’t specified an ORDER BY for that piece in either of these queries, so it’s a gamble. Fixing this requires different methods for the two different aggregation methods.
In STUFF/FOR XML, we’ll apply an ORDER BY to the inner query. For STRING_AGG(), we’ll use WITHIN GROUP (ORDER BY) immediately after the function.
Performance differences between these two are similar to the unordered version, as are the execution plans. With one exception - we have a lot of residual I/O in the STUFF/FOR XML version, to the tune of 151K rows read to return 4600.

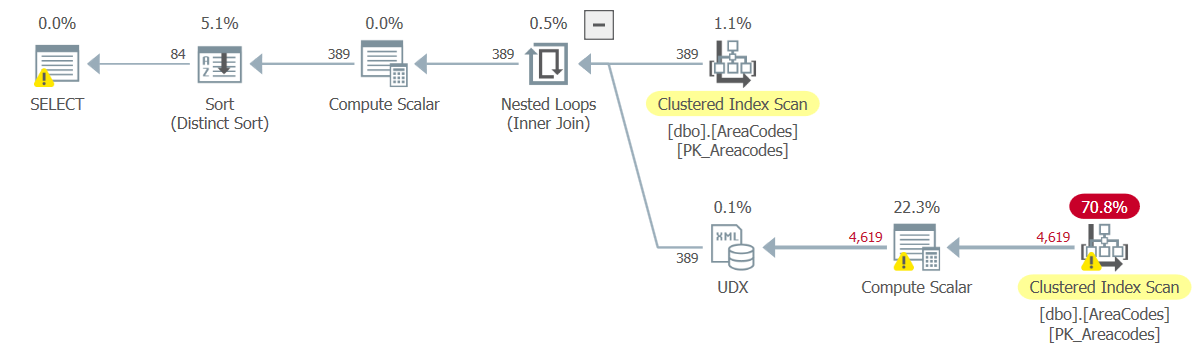
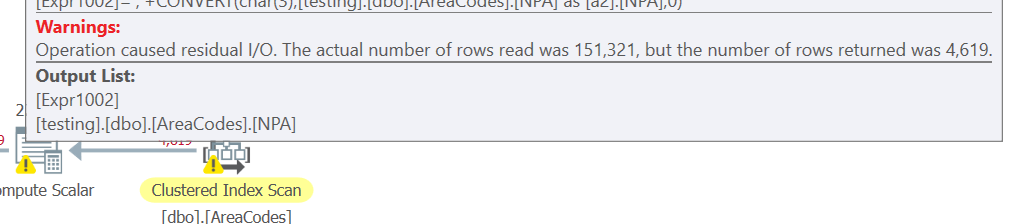
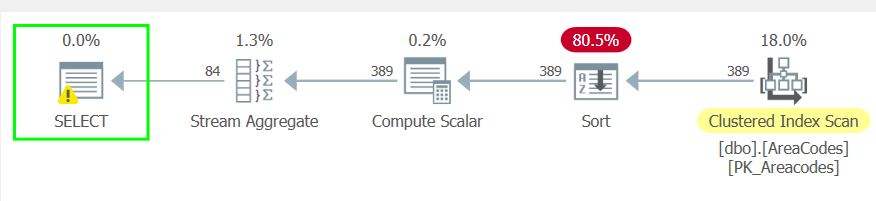
This function looks to be a net win all around.
When Can I Start?
There is no COMPATIBILITY_LEVEL requirement to use STRING_AGG(). You just have to be running on SQL Server 2017 or later. Even if your database is set to COMPATIBILITY_LEVEL 100, this function works!
If you need the aggregated values ordered, WITHIN GROUP (ORDER BY) does require COMPATIBILITY_LEVEL 140 or newer. All the more reason to make that push to complete your upgrade!